在通用int num,for,num++(or,as a ++num)读-写- modify operation is not,原子。但compilers often see for example,the following GCC产生的代码(在这里尝试*):P></
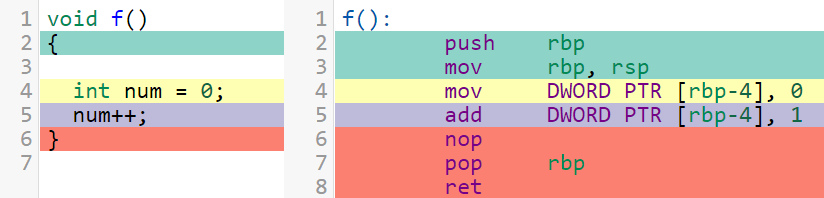 P></
P></
自从5 corresponds在线,which is one to num++指令,我们可以得出结论num++is that this原子在家吗?P></
如果我知道,我知道-它does that generated均值num++can be used in(并发多线程),没有任何危险的竞赛场景数据(即不让我们need to,for example,the Associated std::atomic和实行成本,因为它的原子啊)?P></
更新P></
is not that this question whether时间增量是原子(它是not,is the opening of the和在线的问题)。这是否是它可以是一个场景,即指令是否可以在一定自然好avoid the cases of the剥削的量lock字头。和答案,as the accepted the section在单处理器机器mentions about this as,as the conversation回答的好的意见,在其与其他解释(尽管它可以不与,C或C + +)。P></
- 谁告诉过你add是原子的?
- 考虑到原子的一个特点是在优化过程中防止特定种类的重新排序,不,不管实际操作的原子性如何。
- 您的编译器可能会看到num++可以进行优化,因为您不使用num++的返回值。
- 它仍然需要加载num,增加它,然后写回内存
- 我还想指出,如果这是原子在您的平台上,不能保证它将在另一个PLTAForm上。独立于平台,使用std::atomic表达您的意图。
- 在执行该add指令的过程中,另一个内核可以从该内核的缓存中窃取该内存地址并对其进行修改。在x86 CPU上,如果在操作期间需要在缓存中锁定地址,则add指令需要lock前缀。
- 任何操作都有可能碰巧是"原子的",你所要做的就是运气好,绝不会执行任何会显示它不是原子的操作。原子只是作为一种保证才有价值。考虑到您正在研究程序集代码,问题是特定的体系结构是否恰好为您提供了保证,以及编译器是否提供了保证,即它们选择的程序集级实现。
- 在这种情况下,您的函数是完全安全的,因为其他线程无法访问基于堆栈的num变量。但这可能不是你想要的。(如果您的num是一个全局变量,可能会更好。)
这绝对是C++定义的一种数据竞争,它导致了未定义的行为,即使一个编译器恰好产生了一些目标机器上所希望的代码。为了获得可靠的结果,您需要使用std::atomic,但是如果您不关心重新排序,您可以将它与memory_order_relaxed一起使用。有关使用fetch_add的一些示例代码和asm输出,请参见下文。好的。
但首先,汇编语言是问题的一部分:好的。
Since num++ is one instruction (add dword [num], 1), can we conclude that num++ is atomic in this case?
Ok.
内存目标指令(纯存储除外)是在多个内部步骤中发生的读-修改-写操作。没有修改体系结构寄存器,但是CPU在通过其ALU发送数据时必须在内部保存数据。实际的寄存器文件仅仅是数据存储的一小部分,即使是最简单的CPU,其中锁存着一个阶段的输出,作为另一个阶段的输入,等等。好的。
来自其他CPU的内存操作可以在加载和存储之间全局可见。也就是说,在一个循环中运行add dword [num], 1的两个线程将在彼此的存储中逐步进行。(请参阅@margaret's answer获取一个很好的图表)。从两个线程中的每一个线程增加40K后,在真正的多核x86硬件上,计数器可能只增加了~60K(而不是80K)。好的。
"原子",从希腊词的含义不可分割,意味着没有观察者可以将操作视为单独的步骤。对于所有位同时发生物理/电即时只是一种实现负载或存储的方法,但ALU操作甚至不可能。在我对x86原子性的回答中,我更详细地介绍了纯加载和纯存储,而这个回答主要关注于读-修改-写。好的。
lock前缀可以应用于许多读-修改-写(内存目标)指令,使整个操作对于系统中所有可能的观察者(其他核心和DMA设备,而不是连接到CPU引脚的示波器)具有原子性。这就是它存在的原因。(另请参见本问答)。好的。
所以lock add dword [num], 1是原子的。运行该指令的CPU核心将使缓存线保持在其专用的一级缓存中的修改状态,从加载从缓存读取数据到存储将其结果提交回缓存。根据MESI缓存一致性协议(或多核AMD/Intel CPU分别使用的MOESI/MESIF版本)的规则,这可以防止系统中的任何其他缓存在加载到存储的任何点上拥有缓存线的副本。因此,其他核心的操作似乎发生在之前或之后,而不是在期间。好的。
without the lock字头,一芯线是把所有权of the缓存和后负荷,但在modify恩我们知道,我们的商店,其他商店会成为我们之间globally visible Load和Store。several other answers get this和that没有错,你会得到claim lockof the same conflicting拷贝缓存线。这永远不会发生在我caches与相干系统。>
在locked if(指令缓存存储,在线operates spans两线,它需要很多的工作让更多的部分(the changes to both of the对象传递给他们留下来的原子作为观测器,观测器能看到我不拆除。might have to the lock the Whole CPU总线数据存储记忆until the精选。你不要错位原子元!)>
【注释lockthat the字头也进入安全的内存屏障指令(类mfence)停止运行时,在thus给reordering和顺序一致性。杰夫preshing' EEA(S优秀博客。在他的其他posts是太优秀,解释,和很多好的东西clearly of about无锁编程,和其他从x86硬件details to C++规则)。>
在单处理器机器上,或在单进程单线程的指令,在RMW没有lock字头其实是原子。the only for the Way to other队列访问共享变量is for the context to给交换机的CPU,它不能发生在中间of an指令。我知道我在平原dec dword [num]单线程程序synchronize between and its handlers信号,或在多线程程序在单核机器上运行。see the second another半在线问题回答(我*岁,对我解释它,这在更多的细节。>
C + +:back to
这是完全正常的num++without telling the bogus使用编译器编译它,你需要去读-写-单身执行:modify>
1
2
3
4
| ;; Valid compiler output for num++
mov eax, [num]
inc eax
mov [num], eax |
如果你使用this is the value甚likely of the编译器将一num:keep the增量在登记后的现场。如果你知道如何重新检查自己的在线num++compiles changing the围岩结构,可以影响它的尾巴。>
(if the value不需要后,inc dword [num]is preferred;现代cpus将运行在x86指令目的地记忆的RMW least as as的使用教学efficiently三分开。有趣的事实:人真的会因为这gcc -O3 -m32 -mtune=i586P5(奔腾),是不decode复合管道的超标量微操作简单到多元教学方式及以后的P6微结构。see the agner fog' S /微指令的更多信息的指南,and the many useful for x86标签维基链接(包括英特尔的x86 ISA manuals,which are available frehley as PDF))。>
不要将目标内存模型(x86)与C++内存模型混淆
允许编译时重新排序。使用std::atomic得到的另一部分是对编译时重新排序的控制,以确保您的num++只有在执行其他操作之后才全局可见。好的。
经典示例:将一些数据存储到缓冲区中,以查看另一个线程,然后设置标志。即使X86免费获取加载/释放存储,您仍然必须告诉编译器不要通过使用EDCOX1(1)来重新排序。好的。
您可能期望此代码将与其他线程同步:好的。
1
2
3
4
| // flag is just a plain int global, not std::atomic<int>.
flag--; // This isn't a real lock, but pretend it's somehow meaningful.
modify_a_data_structure(&foo); // doesn't look at flag, and the compilers knows this. (Assume it can see the function def). Otherwise the usual don't-break-single-threaded-code rules come into play!
flag++; |
但不会。编译器可以在函数调用中自由移动flag++(如果它进入函数或知道它不查看flag)。然后,由于flag甚至不是volatile,因此可以完全优化修改。(不,C+EDCOX1,5)不是STD:原子的有用替代物。std::atomic确实使编译器假定可以异步修改内存中的值,类似于volatile,但它的功能远不止这些。另外,正如与@richard hodges讨论的那样,volatile std::atomic foo与std::atomic foo不同。)好的。
将非原子变量上的数据竞争定义为未定义的行为,这使得编译器仍然可以将负载和接收器存储从循环中提升出来,并且可以对多个线程可能引用的内存进行许多其他优化。(有关ub如何启用编译器优化的详细信息,请参阅此llvm日志。)好的。
正如我提到的,x86 lock前缀是一个完整的内存屏障,因此使用num.fetch_add(1, std::memory_order_relaxed);在x86上生成与num++相同的代码(默认为顺序一致性),但在其他架构(如ARM)上,它可以更高效。即使在x86上,relaxed也允许更多的编译时重新排序。好的。
这就是GCC在x86上实际所做的,对于一些在std::atomic全局变量上运行的函数。好的。
请参阅godbolt编译器资源管理器上格式化良好的源代码+汇编语言代码。您可以选择其他目标体系结构,包括ARM、MIPS和PowerPC,以查看从原子中为这些目标获得的汇编语言代码类型。好的。
1
2
3
4
5
6
7
8
9
10
11
12
| #include
std::atomic<int> num;
void inc_relaxed() {
num.fetch_add(1, std::memory_order_relaxed);
}
int load_num() { return num; } // Even seq_cst loads are free on x86
void store_num(int val){ num = val; }
void store_num_release(int val){
num.store(val, std::memory_order_release);
}
// Can the compiler collapse multiple atomic operations into one? No, it can't. |
好的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # g++ 6.2 -O3, targeting x86-64 System V calling convention. (First argument in edi/rdi)
inc_relaxed():
lock add DWORD PTR num[rip], 1 #### Even relaxed RMWs need a lock. There's no way to request just a single-instruction RMW with no lock, for synchronizing between a program and signal handler for example. :/ There is atomic_signal_fence for ordering, but nothing for RMW.
ret
inc_seq_cst():
lock add DWORD PTR num[rip], 1
ret
load_num():
mov eax, DWORD PTR num[rip]
ret
store_num(int):
mov DWORD PTR num[rip], edi
mfence ##### seq_cst stores need an mfence
ret
store_num_release(int):
mov DWORD PTR num[rip], edi
ret ##### Release and weaker doesn't.
store_num_relaxed(int):
mov DWORD PTR num[rip], edi
ret |
注意在顺序一致性存储之后,如何需要mfence(一个完整的屏障)。x86通常是强顺序的,但允许StoreLoad重新排序。拥有一个存储缓冲区对于在无序的流水线CPU上获得良好的性能是至关重要的。JeffPreshing的内存重新排序行为显示了不使用mFence的后果,真实代码显示了在真实硬件上发生的重新排序。好的。
回复:关于@Richard Hodges关于编译器将std::atomic num++; num-=2;操作合并为一个num--;指令的评论中的讨论:好的。
关于同一主题的单独问题:为什么编译器不合并冗余的std::atomic写入?,我的回答重申了我在下面写的很多东西。好的。
当前编译器实际上并没有这样做,但不是因为它们不被允许。C++ WG21/P062R1:编译器应该何时优化原子?讨论了许多程序员认为编译器不会做出"令人惊讶的"优化的期望,以及标准可以给程序员控制。N4455讨论了许多可以优化的例子,包括这一个。它指出,内联和持续传播可以引入像fetch_or(0)这样的东西,即使在原始源没有任何明显的冗余原子操作的情况下,它也可以变成一个load()(但仍然具有获取和释放语义)。好的。
编译器不这样做的真正原因是:(1)没有人编写过复杂的代码,这样编译器就可以安全地(而不会出错)这样做;(2)它可能违反了最不令人惊讶的原则。无锁代码很难一开始就正确地编写。所以不要随意使用原子武器:它们既不便宜,也不会优化很多。但是,使用std::shared_ptr避免冗余的原子操作并不总是容易的,因为它没有非原子版本(尽管这里的一个答案给出了一个简单的方法来定义gcc的shared_ptr_unsynchronized)。好的。
回到num++; num-=2;编译,就好像它是num--一样:除非num是volatile std::atomic,否则编译器可以这样做。如果可以重新排序,则"假设"规则允许编译器在编译时决定它总是以这种方式发生。没有什么能保证观察者能看到中间值(num++结果)。好的。
即,如果这些操作之间没有任何全局可见的排序与源的排序要求兼容(根据抽象机器的C++规则,而不是目标体系结构),编译器可以发射一个EDOCX1×9,而不是EDCOX1,10,EDCX1,11。好的。
num++; num--不能消失,因为它仍然与查看num的其他线程有同步关系,它既是一个获取负载,又是一个发布存储,不允许在此线程中重新排序其他操作。对于x86,这可能能够编译为mfence,而不是lock add dword [num], 0(即num += 0)。好的。
如PR0062中所讨论的,在编译时更积极地合并非相邻的原子操作可能是不好的(例如,进度计数器只在结束时更新一次,而不是每次迭代),但它也可以帮助性能不受负面影响(例如,在创建和销毁shared_ptr的副本时,跳过原子inc/dec-of-ref计数,如果编译器能够证明另一个shared_ptr对象在临时对象的整个生命周期内都存在的话。)好的。
当一个线程立即解锁和重新锁定时,即使是num++; num--合并也可能损害锁实现的公平性。如果它从未在ASM中真正释放过,那么即使是硬件仲裁机制也不会给另一个线程在这一点上获取锁的机会。好的。
在当前的GCC6.2和CLANG3.9中,即使在最明显的优化情况下使用memory_order_relaxed,您仍然可以获得单独的lockED操作。(Godbolt编译器资源管理器,以便查看最新版本是否不同。)好的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| void multiple_ops_relaxed(std::atomic<unsigned int>& num) {
num.fetch_add( 1, std::memory_order_relaxed);
num.fetch_add(-1, std::memory_order_relaxed);
num.fetch_add( 6, std::memory_order_relaxed);
num.fetch_add(-5, std::memory_order_relaxed);
//num.fetch_add(-1, std::memory_order_relaxed);
}
multiple_ops_relaxed(std::atomic<unsigned int>&):
lock add DWORD PTR [rdi], 1
lock sub DWORD PTR [rdi], 1
lock add DWORD PTR [rdi], 6
lock sub DWORD PTR [rdi], 5
ret |
好啊。
- "[使用单独的说明]过去效率更高…但是,现代的x86 CPU再次至少同样有效地处理RMW操作——在更新后的值将在同一个函数中使用的情况下,它仍然更有效,并且编译器有一个可用的寄存器来存储它(当然,变量没有标记为volatile)。这意味着编译器是否为操作生成一条指令或多条指令很可能取决于函数中的其余代码,而不仅仅是相关的单行。
- @Periabreatta:是的,很好。在asm中,可以使用mov eax, 1xadd [num], eax(不带锁前缀)来实现后增量num++,但这不是编译器所做的。
- @彼得卡德斯,你写的"不是物理/电子同时发生",你是说"是不是…"立刻?
- 上帝啊,对原子性的诠释——做得好!考虑为社区做标记吗?
- @Leoheinsaar:同时,我的意思是所有32位都在并行总线上同时发出信号。我写得很快,这样人们还在看这个问题的时候我就能把它贴出来。我有另一个重要的编辑要提交,但点击文本框内部,以某种方式用第三方编辑刷新了我的窗口,并丢失了我的更改:(当然不是彼得的莫特森的错:这是所以的错。谢谢你的编辑。虽然我确实把C++的未定义行为和数据竞争当作是专有名词,而不仅仅是短语的字面意思。
- @彼得命令啊,好的,同时。很遗憾听到丢失的更改,希望您仍能添加它们。
- @兰金:如果你想做任何编辑,请随意。不过,我不想做这个CW。这仍然是我的工作(和我的混乱:p)。我会在最后一场飞盘比赛后整理一下。
- 哦,不,exegesis(定义为对文本的批判性解释)是对您所写内容的一大补充。(和赞成票一起)我不能开始改进它。很抱歉,如果不是这样理解的话。
- @兰金:我理解第一部分,谢谢:)但我认为你的意思是MarkItCommunitywiki。不是吗?
- 如果不是社区wiki,那么可能是适当的标签wiki上的链接。(x86和原子标签?).值得进行额外的链接,而不是通过对S.O.进行一般性搜索来获得有希望的回报(如果我更清楚它在这方面的适用范围,我会这样做的)。我将不得不深入研究标记wiki链接的"注意事项"和"不注意事项")。
- @听起来是个不错的计划。我试图抵制将我自己的答案添加到标签维基,因为许多从x86维基链接的问题已经是我的答案。(我写了这个标签wiki,如果我知道我已经写了一个试图规范化的答案,并且你可以从标签wiki链接到其他答案的话,那么寻找其他答案会更有效。)但是如果你认可这值得指点人们,我会很高兴地将其链接到无锁、stdamico,或者其他相关的标签中。维基:)
- 《PeterCordes优秀答案》,这是我乐于阅读和学习的稿件。谢谢您。
- 答案很好,彼得。
- "编译器可以自由地在函数调用中移动标志+++":EDCOX1(4)有副作用——在函数调用之后,它不应该总是被排序吗?
- @斯宾塞:"假设"规则(非原子对象上的数据竞争是ub)允许它在我指定的特殊情况下这样做:(如果它进入函数或知道它不看flag)。序列点与同步关系不同。如果没有与操作(如atomics或std::mutex)同步,编译器可以执行任何不会更改单线程执行结果的操作。
- @Leoheinsaar:我终于开始做我想做的编辑了。最后一节太长了,我真的应该把它作为一个单独的自问题发布,讨论编译器是否可以优化atomics:p
- @我在x86、无锁和stdamic标签wikis中添加了这个链接。这些都是我以前编辑过的维基。(大型x86标签wiki至少是我工作的95%)。IDK如果它适合C++标签wiki,因为它的FAQ问题没有关于STDATABOM。
- 一如既往-回答得很好!很好地区分连贯性和原子性(有些人错了)
…现在让我们实现优化:
好吧,让我们给它一个机会:
1
2
3
4
5
6
7
8
9
| void f(int& num)
{
num = 0;
num++;
--num;
num += 6;
num -=5;
--num;
} |
结果:
1
2
3
| f(int&):
mov DWORD PTR [rdi], 0
ret |
另一个观察线程(甚至忽略缓存同步延迟)没有机会观察单个更改。
比较:
1
2
3
4
5
6
7
8
9
10
11
| #include
void f(std::atomic<int>& num)
{
num = 0;
num++;
--num;
num += 6;
num -=5;
--num;
} |
如果结果是:
1
2
3
4
5
6
7
8
9
| f(std::atomic<int>&):
mov DWORD PTR [rdi], 0
mfence
lock add DWORD PTR [rdi], 1
lock sub DWORD PTR [rdi], 1
lock add DWORD PTR [rdi], 6
lock sub DWORD PTR [rdi], 5
lock sub DWORD PTR [rdi], 1
ret |
现在,每次修改都是:
在另一条线中可观察到的,以及
尊重在其他线程中发生的类似修改。
原子性不只是在指令级别,它涉及从处理器、通过缓存到内存和内存的整个管道。
进一步信息
关于优化std::atomic更新的效果。
C++标准具有"以貌取人"的规则,它允许编译器重新排序代码,甚至可以重写代码,只要结果具有完全相同的可观察的效果(包括副作用),就好像它简单地执行了代码一样。
假设规则是保守的,尤其涉及原子论。
考虑:
1
2
3
4
| void incdec(int& num) {
++num;
--num;
} |
由于没有互斥锁、原子或任何其他影响线程间排序的构造,我认为编译器可以自由地将此函数重写为nop,例如:
1
2
3
| void incdec(int&) {
// nada
} |
这是因为在C++内存模型中,不可能有另一个线程观察增量的结果。当然,如果num是volatile(可能影响硬件行为),情况会有所不同。但是在这种情况下,这个函数将是修改这个内存的唯一函数(否则程序是格式错误的)。
然而,这是一个不同的球赛:
1
2
3
4
| void incdec(std::atomic<int>& num) {
++num;
--num;
} |
num是一种原子。它的变化必须能被其他正在观察的线程观察到。这些线程本身所做的更改(例如在递增和递减之间将值设置为100)将对num的最终值产生非常深远的影响。
这是一个演示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| #include <thread>
#include
int main()
{
for (int iter = 0 ; iter < 20 ; ++iter)
{
std::atomic<int> num = { 0 };
std::thread t1([&] {
for (int i = 0 ; i < 10000000 ; ++i)
{
++num;
--num;
}
});
std::thread t2([&] {
for (int i = 0 ; i < 10000000 ; ++i)
{
num = 100;
}
});
t2.join();
t1.join();
std::cout << num << std::endl;
}
} |
样品输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| 99
99
99
99
99
100
99
99
100
100
100
100
99
99
100
99
99
100
100
99 |
- 所以一定有同样的缺陷。我已经多次投了赞成票,但它只显示了一次:(。很好的答案,很高兴向大家展示这一切是如何在你身上分崩离析的。
- 这不能解释add dword [rdi], 1不是原子的(没有lock前缀)。加载是原子的,存储是原子的,但是没有什么能阻止另一个线程修改加载和存储之间的数据。因此,存储可以单步执行另一个线程所做的修改。参见jdube.wordpress.com/2011/11/30/Understanding Atomic Operate&zwnj;&8203;ons。另外,JeffPreshing的无锁文章非常好,他在介绍文章中提到了基本的RMW问题。
- 我了解可观察性问题。我只是好奇一个非常简单的可能情况(并且假设没有进行任何优化——这个例子显然是可以优化的,只是为了保持简单)。另外,原子性意味着在操作生效之前,CPU不能被抢占。
- @Leoheinsaar哪个CPU的哪个超线程?那公共汽车呢?这个CPU是否允许中断先发制人指令完成(和管道刷新)。实际上没有指令这样的东西——它只是一系列子操作被推送到操作队列中。
- "另一个观察线程(甚至忽略缓存同步延迟)没有机会观察单个更改"-这实际上是一个问题吗?即使使用std::atomic&,我认为编译器可以自由地将所有这些操作合并到一个操作中。
- @用户2357112是的,因为不能保证任何其他线程都能观察到中间的修改,所以编译器应该能够像优化第二个示例一样优化第三个示例。代码的行为"就像"其他线程从未在正确的时间观察到更改。
- @用户2357112只有证明没有其他线程可能观察到原子变量,它才能这样做。在引用变量的情况下,无法证明没有其他观察者(或编写者)。
- @理查德霍奇斯:是否有一些机制我不知道会让另一个线程确保它看到num需要的每个值?我认为它可以合并操作,表现得好像其他读者和作者从来没有看到过糟糕的时刻。
- @用户2357112:我同意,我认为编译器应该被允许这样做,即使有默认的(顺序一致性)内存排序要求。在同一个变量上有两个原子OPS不被任何线程中的任何负载或存储区分开是C++标准允许的可能排序之一,因此编译器可以在编译时选择它(如罗斯所说)。李察在这里是错误的;没有观察者可以做的事情来保证他们看到中间状态(纯C++,即排除调试器样式监视点)。我在这个问题上加了一节。
- 这里真正发生的是,没有人在GCC中实现这种优化,因为它几乎无用,而且可能比帮助更危险。(最小惊奇的原则)。也许有人期待一个暂时的状态有时可见,并且统计概率是可以的。或者他们使用硬件监视点来中断修改。)无锁代码需要精心设计,因此没有任何优化。寻找它并打印警告,提醒编码人员他们的代码可能不是他们所想的!
- @彼得命令我尊重地不同意你。spinlock是一种结构,其中两个线程都必须能够观察变量的变化。如果编译器看到一个spinlock正在循环中使用,我们不希望它假定其值不会以可观察的方式发生变化。编译器绝对不能删除单个读写操作。另一个例子:如果另一个线程在递增和递减的顺序中间原子地清除num,会发生什么?这种变化必须由我们的函数来观察,否则它将改变可观察的行为。
- @罗斯里奇,我不认为那是真的。比如,考虑实施彼得森的算法。如果您是对的,编译器可能会查看有效地声明flag[0] = true; ...; flag[0] = false;的代码,并确定它可以将更改忽略为flag[0],因为在更改之间可能没有其他线程读取它。这显然不是真的,但要证明这不是真的,所需的分析已经超出了我在任何编译器中所看到的范围。因此,编译器必须假定更改为…
- …原子访问的对象在任何时候都可以在其他线程中观察到,否则它们将以有效地使它们无用的方式破坏常见的算法。
- @在我的回答中的进一步信息下,添加了PeterOrders演示程序。
- @PeriableCreata:关键区别在于Peterson算法中的...,它还修改了全局可见状态(turn=1和锁保护的关键部分)。我们只是在讨论合并时,实际上根本没有合并:num+=1; num-=2。Richard的更新只显示了GCC如何选择编译它,并没有证明它是必需的。代码具有争用条件。不是一个C++UB数据竞赛,只是花园品种竞赛,这意味着结果是不可预知的。100是一个合法的输出,并且没有什么要求某些运行可能产生99。
- @PeterOrders和我确信这会改变另一个线程中的可观察行为,这个线程可能会等待看到值从0变为1,甚至有一段时间。
- 这可能是编译器不实现这一点的原因(最不意外的原则等等)。观察到这在实际硬件上是可能的。然而,C++内存排序规则并没有说明任何保证一个线程的负载在C++抽象机中与其他线程的OP"均匀"混合。我仍然认为这是合法的,但程序员是敌对的。
- 思维实验:在协作多任务系统上考虑C++实现。它通过在需要避免死锁的地方插入屈服点来实现std::thread,但不是在每个指令之间插入。我猜你会认为,C++标准中的某些东西需要EDCOX1×0Ω和EDCOX1×1之间的屈服点。如果你能在标准中找到一个要求的部分,它就会解决这个问题。我敢肯定,这只要求没有观察家能看到错误的重新排序,而这并不需要收益率。所以我认为这只是一个执行问题的质量。
- @彼得哥德斯27.65谈论内存受到影响。在我看来,这似乎是读写必须发生。然而,在某些情况下,学究式的学问通常会留下重要的细节。
- N414027.5.5。2.4注意到"非易失性对象的操作可能在某些条件下合并"。您可以使用volatile atomic来保证您期望的语义。所有原子函数都有易失性和非易失性版本。这并不一定意味着普通的atomic<>对象没有像volatile那样的语义,但是关于合并的评论似乎证实了我的解释。1.10.23说:事实上,大多数单线程程序转换仍然是允许的,因为任何程序的行为不同,因此必须执行未定义的操作。
- @彼得卡德,我担心我们正在进入一个标准的"角落案例"。volatile的效果是完全由实现定义的,因此我们不能合理地讨论使用volatile来确保在所有实现中都发生写操作。此外,我认为我的随机数生成器(上面)不会调用任何未定义的行为。我认为期望(要求)同一数量的商品不能保证会有两次出货是合理的。但我们可能是无聊的人。我会问STD C++论坛。
- 让我们在聊天中继续讨论。
- 为了最终的结果,我在性病讨论邮件列表上问。这个问题出现了两篇似乎都与彼得一致的论文,并解决了我对这些优化的担忧:wg21.link/p062和wg21.link/n4455我感谢安迪,安迪把这些引起了我的注意。
- @理查德霍奇斯:如果编译器编写者使用常识试图以最有用的方式实现事物,而不一定是最"有效"的方式,那么这个标准就很好了。如果编译器展开一个4x循环,那么合并包含四个更新的组是合理和有用的。如果编译器可以估计循环将花费多长时间,则使用寄存器中的计数器将更新限制为将更新时间限制为5%的循环时间的速率可能很有用。但是,在六小时的循环中整合所有更新,直到结束,并没有那么有用。
没有很多并发症,像add DWORD PTR [rbp-4], 1这样的指令是非常cisc风格的。
它执行三个操作:从内存加载操作数,增加操作数,将操作数存储回内存。在这些操作中,CPU获取和释放总线两次,在任何其他代理之间也可以获取总线,这违反了原子性。
1
2
3
4
5
6
7
8
| AGENT 1 AGENT 2
load X
inc C
load X
inc C
store X
store X |
X只递增一次。
- @为了做到这一点,每个存储芯片都需要自己的算术逻辑单元(ALU)。实际上,它要求每个存储芯片都是一个处理器。
- @leoheinsaar:内存目标指令是读-修改-写操作。没有修改体系结构寄存器,但是CPU在通过其ALU发送数据时必须在内部保存数据。实际的寄存器文件仅仅是数据存储的一小部分,即使是最简单的CPU,其中锁存着一个阶段的输出,作为另一个阶段的输入,等等。
- @彼得卡德,你的评论正是我想要的答案。玛格丽特的回答让我怀疑里面一定有这种事。
- 把这个评论变成一个完整的答案,包括解决这个问题的C++部分。
- "PeterCordes Thanks,非常详细,所有的要点。显然,这是一个数据竞争,因此C++标准的行为是不明确的,我只是好奇,在生成代码是我发布的情况下,人们可以假设它可以是原子等。我还检查了至少英特尔开发人员手册非常清楚地定义了相对于内存操作的原子性,而不是英特尔。UCITE不可分割,正如我所假设的:"锁定操作相对于所有其他内存操作和所有外部可见事件都是原子的。"
添加指令不是原子指令。它引用内存,并且两个处理器内核可能具有该内存的不同本地缓存。
添加指令的原子变量称为lock xadd
- EDOCX1 5实现C++的STD::原子EDCOX1,6,返回旧的值。如果不需要,编译器将使用带有lock前缀的普通内存目标指令。lock add或lock inc。
- 在没有缓存的SMP机器上,add [mem], 1仍然不是原子的,参见我对其他答案的评论。
- 查看我的答案,了解更多关于它如何不是原子的细节。我对这个相关问题的回答也到此结束。
Since line 5, which corresponds to num++ is one instruction, can we conclude that num++ is atomic in this case?
基于"逆向工程"生成的装配得出结论是危险的。例如,您似乎已在禁用优化的情况下编译了代码,否则编译器会丢弃该变量或直接将1加载到它,而不调用operator++。因为生成的程序集可能会发生显著的变化,基于优化标志、目标CPU等,所以您的结论是基于sand的。
另外,您认为一条汇编指令意味着一个操作是原子的想法也是错误的。这个add在多CPU系统上,甚至在x86体系结构上,都不是原子的。
即使你的编译器总是把它作为原子操作来发射,同时从任何其他线程中访问EDCOX1×0,将根据C++ 11和C++ 14标准构成一个数据竞争,程序将有未定义的行为。
但比这更糟。首先,如前所述,编译器在增加变量时生成的指令可能取决于优化级别。其次,如果num不是原子的,编译器可以重新排序++num周围的其他内存访问,例如。
1
2
3
4
5
6
7
8
9
10
11
12
13
| int main()
{
std::unique_ptr<std::vector<int>> vec;
int ready = 0;
std::thread t{[&]
{
while (!ready);
// use"vec" here
});
vec.reset(new std::vector<int>());
++ready;
t.join();
} |
即使我们乐观地假设++ready是"原子的",并且编译器根据需要生成检查循环(如我所说,它是ub,因此编译器可以随意删除它,用无限循环替换它,等等),编译器仍然可能移动指针分配,甚至更糟的是,vector的初始化到p增量操作后的点,导致新线程中的混乱。实际上,如果一个优化编译器完全删除了ready变量和检查循环,我一点也不会感到惊讶,因为这不会影响语言规则下的可观察行为(与您的私人希望相反)。
事实上,在去年的会议C++会议上,我从两个编译器开发人员那里听说,他们非常乐意执行优化,使语言编写的多线程程序行为不当,只要语言规则允许,即使在正确编写的程序中看到微小的性能改进。
最后,即使您不关心可移植性,而且您的编译器非常好,您使用的CPU很可能是一种超标量的cisc类型,它会将指令分解为微操作、重新排序和/或推测地执行它们,在某种程度上,仅限于同步诸如(在Intel上)LOCK前缀或mem之类的原语。ORY围栏,以最大化每秒操作。
长话短说,线程安全编程的自然责任是:
您的职责是编写在语言规则(特别是语言标准内存模型)下具有良好定义行为的代码。
编译器的职责是生成在目标体系结构的内存模型下具有相同定义良好(可观察)行为的机器代码。
CPU的职责是执行这段代码,以便观察到的行为与它自己的体系结构的内存模型兼容。
如果你想用你自己的方式来做,它可能在某些情况下是有效的,但是要理解保证是无效的,并且你将对任何不想要的结果负全部责任。-)
附:正确书写的示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
| int main()
{
std::unique_ptr<std::vector<int>> vec;
std::atomic<int> ready{0}; // NOTE the use of the std::atomic template
std::thread t{[&]
{
while (!ready);
// use"vec" here
});
vec.reset(new std::vector<int>());
++ready;
t.join();
} |
这是安全的,因为:
ready的检查不能根据语言规则进行优化。
++ready发生在检查认为ready不是零之前,其他操作不能围绕这些操作重新排序。这是因为EDCOX1 3和检查顺序一致,这是C++内存模型中描述的另一个术语,禁止这种特定的重新排序。因此,编译器不能对指令重新排序,也必须告诉CPU它不能将对vec的写入推迟到ready的增量之后。顺序一致性是语言标准中关于原子的最有力的保证。较低(理论上更便宜)的保证可用,例如通过std::atomic的其他方法,但这些绝对仅适用于专家,编译器开发人员可能不会对其进行太多优化,因为很少使用它们。
- 如果编译器看不到ready的所有用法,它可能会将while (!ready);编译成更像if(!ready) { while(true); }的东西。upvoted:std::atomic的一个关键部分正在改变语义,以在任何时候假设异步修改。它通常是ub,这使得编译器能够将负载和接收器存储从循环中提升出来。
在单核x86机器上,相对于CPU1上的其他代码,add指令通常是原子的。中断不能把一条指令从中间分割开。
无序执行是为了在一个内核中保持一个指令一次执行一个指令的假象,所以在同一个CPU上运行的任何指令要么完全发生在添加之前,要么完全发生在添加之后。
现代x86系统是多核的,因此单处理器的特殊情况不适用。
如果目标是一台小型嵌入式PC,并且没有计划将代码移动到其他任何地方,那么"添加"指令的原子性质就可以被利用。另一方面,操作本身具有原子性的平台变得越来越稀缺。
(如果你用C++编写,这对你没有帮助。编译器没有选择要求num++编译到没有lock前缀的内存目标add或xadd。他们可以选择将num加载到寄存器中,并用单独的指令存储增量结果,如果使用结果,则很可能会这样做。)
注1:lock前缀甚至存在于原来的8086上,因为I/O设备与CPU同时运行;单核系统上的驱动程序需要lock add自动增加设备内存中的值,如果设备也可以修改它,或者关于DMA访问。
- 它甚至不是一般的原子:另一个线程可以同时更新同一个变量,只接受一个更新。
- @当然在8088和80286上,任务切换的中断只能在指令之间发生。80386增加了页面错误的可能性,但是中断的指令将从头开始。我还没有跟踪到后来芯片内部工作的所有变化,但是我认为重新启动的方法已经被保留了。
- 考虑一个多核系统。当然,在一个核心中,指令是原子的,但就整个系统而言,它不是原子的。
- 中断发生在两个指令之间,不能将RMW从中间拆分。例如,在一个up系统上,这样可以安全地在内核和中断处理程序之间进行同步(请参阅这里我的答案的后半部分,以及关于这个问题的部分答案)。但是un-lockedinsns不适合在MMIO寄存器或设备内存上执行原子RMW。由于这个原因,在SMP CPU之前就存在lock前缀:断言锁定总线信号。
- @我回答的第四和第五个字是什么?
- @彼得卡德斯:使用dma修改rmw指令目标的系统需要"锁",但我发现很难想象想要这样做。我不认为锁前缀对大多数类型的内存映射I/O有任何作用,因为要么寄存器总是读取写入的值(在这种情况下,锁是不必要的),要么响应总线上的内存写入请求以外的事情而改变(这通常是锁会阻止的唯一事情)。
- 我不太清楚在8086这样的SMP之前的硬件中,究竟使用了什么lock。我检查了一下,锁是原来8086的一部分,而不仅仅是为SMP添加了386。您会将它用于一个网卡吗?当主机CPU读写保存数据包的缓冲区时,该网卡必须与主机CPU同步?可能是从网卡上的设备内存,如果不是通过DMA。
- @超级卫星你的回答是非常误导,因为它只考虑目前罕见的单一核心的情况,并给OP一个错误的安全感。这就是为什么我评论要考虑多核案例的原因。
- @我做了一个编辑,为那些没有注意到这不是在谈论普通的现代多核CPU的读者澄清潜在的困惑。(也更具体一些超级卫星不确定的东西)。顺便说一句,这个答案中的所有内容都已经在我的系统中了,除了最后一句关于read-modify-write平台如何"免费"是原子的,这是很少见的。
- 为了这个目的,我认为对齐并不重要。中断不会在指令的一部分完成时发生。不过,这是使用锁前缀的要求。
- JD?乌戈斯:没错,对齐没关系。它只是使单独的加载和存储操作成为原子操作。(在p6和更新版本上,64位或更小的加载和存储是原子的,只要它们不跨越缓存线边界。)lock add在未对齐的地址上工作,但如果它跨越缓存线边界,则速度可能很慢。AMD的优化手册IIRC说,它需要一个总线锁来锁定不自然对齐的锁定操作(而不仅仅是受影响线路上的缓存锁)。
- JD?Ugosz:如果操作没有对齐,并且目标的一半在写保护页中,那么在页错误期间发生的中断可能会看到写值的下半部分,而上半部分不在。
- @超级卫星:你上次的评论不对。页面拆分存储区上的页面错误将导致在执行异常之前取消存储区的两部分。只有像avx512 scatter、rep stos或其他显式可重新启动的指令这样的东西才能在架构上部分完成,然后进行异常处理。它们使寄存器值保持更新,以避免将同一数据存储到同一位置两次(架构上)。因此,当页面错误结束时,指令会使用不同的输入重新执行,这些输入不会存储到任何已经完成的位置。
- @彼得:有趣。让指令一次控制多个页面会使事情变得复杂,但我想英特尔愿意为此付出代价。一直到80386,是这样吗?
- 我想应该是。如果没有存储队列或真正的管道,我假设386只会在执行任何一个存储之前检查两个页面的权限,而不是在让它们提交到L1D之前。(可能是在页面拆分存储的缓慢回退中,可能是微编码的)。即使在Broadwell上,页面分割加载/存储也有巨大的损失,比如每140个周期的吞吐量,而在Skylake上,每5个周期就有一个这样的损失,所以直到最近,Intel才最终构建了真正优化的硬件来处理页面分割,而不需要缓慢的回退来纠正它。)
- @PeterOrders:在80386上,任何不完全属于单个32位字的写操作,除了在TLB丢失的情况下需要的任何页表查找外,都保证会为存储产生两个单独的总线周期。在第一页查找完成后立即启动第一个总线周期将允许在执行该总线周期时对第二个地址进行TLB查找。也许Intel在第一个地址上操作之前等待第二次TLB查找,或者Intel使用了……
- …可以同时查找两个连续页面的TLB硬件(例如,对偶数页和奇数页使用一个TLB),但将拆分存储的两部分视为独立的,似乎比在第一个存储之前同时进行两个TLB查找更能实现速度和复杂性的更好组合。
- @Supercat:idk什么是性能惩罚386。我预计延迟的可能性更大;对于某些访问模式,拆分TLB的效率会更低。在设计p6的时候,现有代码中的页面分割肯定是罕见的,否则在Skylake之前,它不会一路吸这么多。在搜索时,我发现了一个Intel386SX数据表,它确认了页面错误会阻止"传输整个内存量"。我没有发现任何更具体提到页面分裂,但TLB是一个单32条目。
- 即使是一个最核心的操作系统,我认为也有一些程序可以指定它们只使用一个内核。如果有足够的其他工作来保持所有内核忙,消除对多处理器协调的需要可以提高整体效率[单核任务可能不能像运行多核一样运行得那么快,但将占用更少的总CPU时间远离其他任务]。
在X86计算机有一个CPU的日子里,使用一个指令确保中断不会分割读/修改/写,如果内存也不被用作DMA缓冲器,它实际上是原子的(C++没有提到标准中的线程,所以没有解决这个问题)。
当在客户桌面上很少有双处理器(例如双插槽Pentium Pro)时,我有效地使用了它来避免单核机器上的锁前缀并提高性能。
今天,它只对设置为相同CPU关联性的多个线程有帮助,因此您担心的线程将只通过在同一个CPU(核心)上过期并运行另一个线程来发挥作用。这不现实。
在现代x86/X64处理器中,单个指令被分解成若干个微操作,并且内存读写被缓冲。因此,在不同CPU上运行的不同线程不仅会将此视为非原子的,而且可能会看到与它从内存中读取的内容以及它假定其他线程已读取到该时间点的内容有关的不一致的结果:您需要添加内存边界来恢复正常的行为。
- 中断仍然不拆分RMW操作,因此它们仍然将单个线程与在同一线程中运行的信号处理程序同步。当然,这只在ASM使用单个指令时有效,而不是单独的加载/修改/存储。C++ 11可以公开这种硬件功能,但它不可能(可能是因为它在单处理器内核中非常有用,以便与中断处理程序同步,而不是在信号处理程序的用户空间中)。另外,体系结构没有读-修改-写内存目标指令。不过,它可以像非x86上的放松原子RMW一样进行编译。
- 不过,我记得,在超级分频器出现之前,使用锁前缀并不是非常昂贵。所以没有理由注意到它会减慢486中的重要代码,即使该程序不需要它。
- 是的,对不起!实际上我没有仔细阅读。我看到段落的开头有一条关于解码为Uops的红鲱鱼,但没有读完你说的话。回复:486:我想我已经读到最早的SMP是某种Compaq 386,但是它的内存排序语义与x86 ISA当前所说的不同。当前的x86手册甚至可能提到SMP486。不过,我认为,在ppro/athlon xp时代之前,即使是在hpc(beowulf集群)中,它们也不常见。
- 我记得一篇用计算机语言或386/486时代的某个地方写的关于多CPU板的社论,以及在Unix下它是如何改变一切的,因为它们有很多不同的进程在运行。但是在ZoTeCo之前,在"386时代机器"上运行C++编译器是非常不切实际的,尽管有几个品牌将基于cFAX的实现推向市场。
- 你的前两段准确地描述了我在最初的问题中直觉上想到的技巧(我的兴趣是理论上的)。只是没有在一个单一的核心系统中制定它。好的,让我们把它从C++中分离出来,假设我用手工写了一段ASM,我在一个核心系统上,所以线程上下文切换CPU时间。在这种情况下,我是否有权假定add指令实际上是原子的(从某种意义上说,它的效果可以作为一个单一步骤观察到),并且我可以避免锁定add,就像你以前说的那样?还有,@petercordes?
- 所有相关的线程都有CPU亲和力,这有什么理由是"不现实"的吗?如果一个人有足够多的不同的作业,即使一次只能在一个CPU上运行多个特定的任务(例如,四个CPU可以运行四个独立的任务),也可以使所有的核心保持忙碌,我认为能够将任务指定为仅限于一个CPU,然后消除所有的任务内内存互锁可能是十是一场表演胜利。
- @使用抢占线程的supercat在运行一个需要等待另一个从干燥部分出来的线程时会失去效率。有了多个核心,我们已经转移到低开销的spinlocks。要按照你的建议去做,你将一直走到非抢占式的像纤维或await结构。我没有考虑的是嵌入式系统和异步信号;这可能有助于减少锁的开销,在理解良好的条件下。
- @Leoheinsaar是的:中断总是在asm指令和刷新管道等之间进行,因此在那些指定的条件下,它似乎是一个旧的一次性CPU到软件。只有小助手函数需要用asm手工编码。
- @是的,非locked add works。@supercat的答案有同样的意义,我的答案中的单处理器部分也是如此。除非有任何dma/设备观察器(例如,您正在为网卡编写一个驱动程序,该网卡还设置标志以指示数据包缓冲区现在包含一个有效的数据包),在这种情况下,您确实需要lock add使其相对于系统中的非CPU观察器具有真正的原子性。另请参阅此答案的后半部分,以及讨论非CPU观察员的评论中的讨论。
- @超级卫星:有趣的一点。是的,这可能会减少在使用线程进行I/O或类似操作时的开销,因此它们通常在不持有任何锁的情况下休眠。您可以通过在没有锁的地方添加sched_yield()调用来调优这样的系统。JD?乌戈斯:我觉得你说的太多了。如果关键部分很短而且不经常出现,那么线程通常不会在关键部分内占用它们的时间片。这可能是为非CPU绑定程序提供线程便利性的一个好方法。
- JD?UGOZZ:如果一个锁只用于在单个内核上同步单个进程中的操作,并且线程试图进入另一个线程所获取的锁,则不必花费CPU时间"等待"任何东西——将执行立即转移到持有锁的线程。
- 彼得科德斯好。当然,假设也没有DMA/设备观察员-不适合在评论区,包括一个也。谢谢JD?Ugosz的优秀添加(答案和评论)。真的完成了讨论。
- @利奥:有一个关键点没有被提到:不正常的CPU确实在内部重新排序,但黄金法则是对于单个内核,它们保留了一次运行一条指令的错觉。(这包括触发上下文切换的中断)。值可能是不按顺序电存储到内存中的,但是所有东西都在运行的单核跟踪它自己所做的所有重新排序,以保留这种错觉。这就是为什么您不需要内存屏障,ASM相当于a = 1; b = a;来正确加载刚刚存储的1。
- JD?Ugosz:如果一个进程只使用一个内核,并且锁定原语是为此而设计的,那么在有争议的锁案例上线程切换所需的时间可能小于获取和释放由另一个内核持有但在其他方面未经测试的锁所需的时间。
不。https://www.youtube.com/watch?V= 31 G0YY61PLQ(这只是从"办公室"到"不"场景的链接)
您是否同意这是程序的一个可能输出:
样品输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| 100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100
100 |
如果是这样,那么编译器就可以自由地以编译器想要的任何方式将其作为程序的唯一可能输出。也就是说,一个只输出100秒的主函数。
这是"好像"规则。
不管输出是什么,你都可以用同样的方法来考虑线程同步——如果线程A执行num++; num--;,而线程B重复读取num,那么一个可能的有效交织就是线程B从未在num++和num--之间读取。由于这种交织是有效的,编译器可以自由地使之成为唯一可能的交织。完全移除增量/增量。
这里有一些有趣的含义:
1
2
| while (working())
progress++; // atomic, global |
(例如,假设其他线程更新了基于progress的进度条用户界面)
编译器能否将其转换为:
1
2
3
4
5
| int local = 0;
while (working())
local++;
progress += local; |
可能是有效的。但可能不是程序员所希望的:-(
委员会仍在研究这方面的问题。目前它"有效"是因为编译器不太优化原子。但这正在改变。
即使progress也不稳定,这仍然有效:
1
2
3
4
5
6
| int local = 0;
while (working())
local++;
while (local--)
progress++; |
- -
- 这个答案似乎只是回答了理查德和我正在思考的一个附带问题。我们最终解决了:事实证明,是的,C++标准确实允许在非EDCOX1×0原子对象上的操作合并,当它不破坏任何其他规则时。两个标准讨论文档讨论了这一点(Richard评论中的链接),其中一个使用相同的进度反例。因此,直到C++标准化了防止它的方法,这才是实现质量的问题。
- 是的,我的"不"实际上是对整个推理过程的回应。如果问题仅仅是"能否num++在某些编译器/实现上是原子的",那么答案是肯定的。例如,编译器可以决定将lock添加到每个操作中。或者一些编译器+单处理器的组合,它们都没有重新排序(即"好日子"),一切都是原子的。但这有什么意义呢?你不能真的依赖它。除非你知道这就是你写作的目的。(即便如此,最好是Atomic在该系统上不添加额外的操作。所以你还是应该写标准代码…)
- 注意,And just remove the incr/decr entirely.并不完全正确。它仍然是num上的一个获取和发布操作。在x86上,num++;num--可以编译为mfence,但绝对不是什么。(除非编译器的整个程序分析能够证明num的修改不会使任何内容同步化,并且如果从之前的存储推迟到从之后的加载之后才进行存储,这并不重要。)例如,如果这是一个立即解锁和重新锁定的用例,您仍然有两个独立的关键部分(可能使用mou-relaxed))不是一个大的。
- @彼得命令啊,是的,同意。
在特定的CPU体系结构上,禁用优化的单个编译器的输出(因为在快速和肮脏的示例中进行优化时,GCC甚至不将++编译为add)似乎意味着以原子方式递增并不意味着这符合标准(在尝试访问E时,会导致未定义的行为)。线程中的docx1(2),无论如何都是错误的,因为add在x86中不是原子的。
注意,atomics(使用lock指令前缀)在x86上相对比较重(请参阅相关答案),但仍然明显小于mutex,这在这个用例中并不太合适。
在使用-Os编译时,以下结果取自clang++3.8。
通过引用递增一个int,"常规"方法:
1
2
3
4
| void inc(int& x)
{
++x;
} |
这包括:
1
2
3
| inc(int&):
incl (%rdi)
retq |
增加通过引用传递的int,原子方式:
1
2
3
4
5
6
| #include
void inc(std::atomic<int>& x)
{
++x;
} |
这个例子并不比常规的方法复杂得多,只是将lock前缀添加到incl指令中,但是要小心,正如前面所说,这并不便宜。仅仅因为组件看起来很短并不意味着它很快。
1
2
3
| inc(std::atomic<int>&):
lock incl (%rdi)
retq |
是的,但是……
原子不是你想说的。你可能问错了。
增量当然是原子的。除非存储未对齐(而且由于您保持了对编译器的对齐,所以它没有对齐),否则它必须在单个缓存线内对齐。缺少特殊的非缓存流指令,每个写操作都会通过缓存。完整的缓存线被原子地读写,没有任何不同。当然,小于cache line的数据也是原子写入的(因为周围的缓存线是)。
它是线程安全的吗?
这是一个不同的问题,至少有两个很好的理由可以肯定地回答"不!".
首先,有可能另一个内核在l1中拥有该缓存线的副本(l2和向上通常是共享的,但l1通常是每个内核!),并同时修改该值。当然,这也是原子性的,但是现在你有了两个"正确的"(正确的,原子性的,修改过的)值——现在哪个值是真正正确的?当然,CPU会以某种方式进行处理。但结果可能不是你所期望的。
第二,有内存排序,或者在保证之前有不同的措辞。原子指令最重要的不是原子指令。这是订货。
你有可能强制保证所有发生记忆的事情都是在一些有保证的、明确定义的订单中实现的,在那里你有一个"以前发生过的"保证。这个排序可以是"放松"(读为:根本没有)或严格按照你的需要。
例如,可以设置指向某个数据块的指针(例如,一些计算的结果),然后原子性地释放"数据就绪"标志。现在,任何获得这个标志的人都会认为指针是有效的。事实上,它始终是一个有效的指针,不会有任何不同。这是因为指针的写入发生在原子操作之前。
- 加载和存储分别是每个原子操作,但整个读-修改-写操作作为一个整体肯定不是原子操作。缓存是一致的,所以永远不能保存同一行的冲突副本(en.wikipedia.org/wiki/mesi_协议)。当另一个内核处于修改状态时,它甚至不能有只读副本。使它成为非原子的是,执行RMW的核心可能会失去负载和存储之间的缓存线的所有权。
- 另外,不,整个缓存线并不总是原子性地传输。请看这个答案,在这里,实验证明了一个多插槽Opteron通过使用HyperTransport将缓存线以8b块的形式传输,使16b SSE存储非原子性,即使它们对于同一类型的单插槽CPU是原子性的(因为加载/存储硬件有一个16b路径到一级缓存)。x86只保证独立加载或存储的原子性高达8b。
- 保持对编译器的对齐并不意味着内存将在4字节边界上对齐。编译器可以有选项或pragma来更改对齐边界。例如,这对于在网络流中对紧密打包的数据进行操作非常有用。
- 索菲亚特,别无他物。带有自动存储的整数(如示例所示,它不是结构的一部分)将绝对正确地对齐。声称任何不同的事情都是完全愚蠢的。缓存线和所有的pod都是pot(2的力量)大小和对齐的——在世界上任何非虚幻的架构上。数学认为,任何一个适当对齐的罐子正好适合任何其他大小相同或更大的罐子中的一个(永远不会更多)。因此,我的陈述是正确的。
- @戴蒙:是的,我同意任何健全的系统都会将int静态全局或自动本地对齐到单独的负载或存储成为原子所必需的任何对齐。你的评论是正确的。但是你的答案仍然使用错误的推理来解释发生了什么。添加指令不会自动读取、修改、写入缓存线(不带锁前缀),同一缓存线的冲突副本不存在。我之前的评论证明缓存线并不是在所有x86系统中原子地传输的。(尽管我认为这是一个罕见的特殊情况,而且大多数x86都有这种情况)
- 答案的排序部分是正确的,但这与num++是否是原子无关:内存的"顺序"原子增量仍然会得到正确的总数(即使在允许不同asm的ARM上也是如此)。x86原子RMW总是需要一个锁前缀,这给了mo-seq-cst语义,因为它也是一个完整的内存屏障。arm,otoh,可以使用load-linked/store条件来执行原子RMW,甚至不需要获取/释放语义,但是缓存一致性仍然可以确保多个线程通过这种方式增加一个共享计数器,从而获得"预期的"总数。
- 达蒙,在这个问题中给出的例子没有提到结构,但是它并没有把问题缩小到只有整数不是结构部分的情况。豆荚绝对可以有罐大小,不罐对齐。看看这个语法示例的答案:StasOfFuff.com /A/11772440/1219722。因此,它几乎不是一个"诡辩",因为以这种方式声明的POD在实际代码中在网络代码中使用相当多。
当编译器只使用一条指令来执行增量,并且您的机器是单线程的,那么您的代码是安全的。^ ^
尝试在非x86计算机上编译相同的代码,您很快就会看到非常不同的汇编结果。
num++看起来是原子的原因是因为在x86机器上,增加32位整数实际上是原子的(假设没有进行内存检索)。但这既不是由C++标准保证的,也不是在不使用x86指令集的机器上的情况。所以这个代码不是跨平台安全的,不受比赛条件的影响。
即使在x86体系结构上,您也不能很好地保证此代码不受竞争条件的影响,因为除非特别指示,否则x86不会将加载和存储设置到内存中。因此,如果多个线程试图同时更新这个变量,它们可能最终会增加缓存(过时)值。
那么,我们有EDOCX1[1]等等的原因是,当您使用的体系结构不能保证基本计算的原子性时,您有一种机制可以强制编译器生成原子代码。
- "因为在x86机器上,增加32位整数实际上是原子的。"你能提供证明它的文档的链接吗?
- 它也不是x86上的原子。它是单核安全的,但是如果有多个核(并且有)它根本不是原子的。
- x86 EDOCX1 0实际上是保证原子的吗?如果寄存器增量是原子的,我不会感到惊讶,但这几乎没用;要使寄存器增量对另一个线程可见,它需要在内存中,这需要额外的指令来加载和存储它,删除原子性。我的理解是,这就是为什么存在用于指令的lock前缀;唯一有用的原子add适用于未引用的内存,并使用lock前缀确保在操作期间锁定缓存线。
- @我更新了答案。add是原子的,但我明确表示,这并不意味着代码是种族条件安全的,因为更改不会立即在全球可见。
- @但是,从定义上讲,它是"非原子"的。
 P></
P></